The quest to the platform #
This article summarizes a real case evolving from just "development infrastructure" in a traditional dev and ops approach to a today's trendy platform.
The origins #
The point was about to be reached in which the traditional waterfall model was limiting all business operations. Of course, the IT ones too. The panorama on the IT side was difficult to evaluate, though. Very few visibility on what applications were being run and their dependencies. A 4 time a year release approach was the standard and in this each 4 windows, all the modifications that business needed, had to be placed in, tested and activated for the customers.
Not only the risk was high, the delays were constant too. The difficulties couldn't be previewed or isolated. They were just met when moving a certain technical component - a component that implements business functionality - between environments progressing up in the integration with the others until production.
Work was very intense between dev and ops and communication was itself a task. The workflow was that Dev would provide the changes that business wanted and ops would put them into production. If those changes wouldn't fit in - and that would happen often - ops would then be back to dev in search for help. The knowledge of the other's environment was reduced so those discussions were not that effective and problems would be solved out of hours of learning under pressure.
The break with the old world #
The most visible and transparent part of the architecture by then were the new applications based on modern technologies. Those technical components - based in modern languages of the 90s and 00s - were smaller than the other technical components - based in integrated stacks of hardware and software - and didn't need complete integration with the operating system to run. They needed other "glue" technical components to the operating system, though. The developers working with these modern technical components had grown up with the possibility of developing projects like that in their own PCs instead of in corporative mainframes. The first tip of dev into ops was that such a component based on those modern technologies could be run in a local development machine.
The modern technical components brought the first - small - revolution. They forced the Ops to be more flexible: Hardware could be dimensioned and installed by Ops and Dev could install the technical components in pre-allocated locations on self-service basis instead of rigid installation procedures of the whole stack as the old ones. This new approach enabled the staging and integration to be done by Devs with less dependency of Ops too though production deployments were not yet so flexible.
Learnings of the first approach #
This concept was validated and put in place for all those modern technical components. The biggest outcome was that the work of dev and ops less prone to friction: The knowledge of each other's environments was still minimal but at least a clear interface between them had been defined.
Moving this workflow into scale brought some stakeholders in to the workflow in a more transparent and reliable manner as before as well: The quality controls could be part of the first steps of the development - as traditional waterfall model. They could be neglected, though, in the way to production in case the software would be failing and needed mending. Which was kind of happening often because of the integration difficulty of such a clunky ecosystem - signalization between components was based on human networks.
The landscape at this point showed that, despite the high customization needed pro technical component, some "types" of technical components could be determined: Frontends, backends, infrastructure...
The organization itself had been modified to accomodate to this new workflow in a proto-devops way. A mid layer - the system teams - was added so that those types of technical components had a responsible and a common team - as a kind of SRE team - would organize the funneling of the technical components into production to the ops teams: The new responsible teams were an improvement because they could interface to the devs and offer them better framework solutions to their technical components so that the integration between technical components would be less prone to error but still a bottleneck was made with the SRE team since it had to support very sparse topics.
The most important learning was perhaps that the development process was custom for almost each technical component and this was causing most of the frictions in the way of the technical components to production out of misalignments both in time of development and shape of them.
The cloud makes the platform more necessary than ever #
The cloud became strategical - out of a management strategical decision - and in this context the standardization became key. Building on top of the first learnings, the choices were consequent: Only the modern technical components - in types - would be migrated to the cloud and the customization would be minimal so that the number of runtimes could always be kept under control. Exotic use cases would be considered and brought in at a later stage in case they'd be strong enough.
There were several challenges that had to be addressed, however:
- No split between dev and ops anymore in the cloud
- The cloud runtimes were - and are - very different to the on-prem ones and a lot of new know-how must be absorbed to use them
- The technical components to be migrated had to find an "easy" and efficient path to the cloud
- The stakeholders demanded that the quality would always be taken into account during the lifecycle of the technical components
- Transparency on the development status of each technical component was more than ever a must so that the friction on adding features could be minimized
- The pressure on the SRE team had to be decreased so that it could still act effectively
These challenges painted the idea that the current organizational split in the system teams - teams that face the devs and team that faces the ops - had to be revisioned because DevOps had to be implemented and that the way the technical components would be reaching production had to be streamlined and all stakeholders brought together into it at anytime.
As a result of these constraints and Conway's law, the organization was reshaped and the architecture of the technology stacks was applied to the whole components that will be migrated to the cloud runtimes.
This is:
- Feature teams - teams dedicated to implement business functionality - own completely the technical components during the whole development and lifecycle. They practice DevOps
- The development process is standardized and every technical component follows it in its way to production
- The runtime is standardized and every technical component uses it according to its "type"
- The "types" of technical components will be called technology stacks and will provide the technical components a standardized development process implementation together with the needed infrastructure to be able to operate in the standard runtimes
- Every technology stack is owned by a system team that is specialist in the technology and target runtime
- The development process is owned by a system team that is specialist in it and provides the needed transparency to the stakeholders
- The development process is implemented by different tools but the part of the process that deals with the technical components moving in into production is centralized in a service that standardizes it for all the technology stacks
First version of the platform is up #
This first platform implementation is based on two columns:
- The development process and its thorough automation
- The access to the platform and the governance over the users' actions
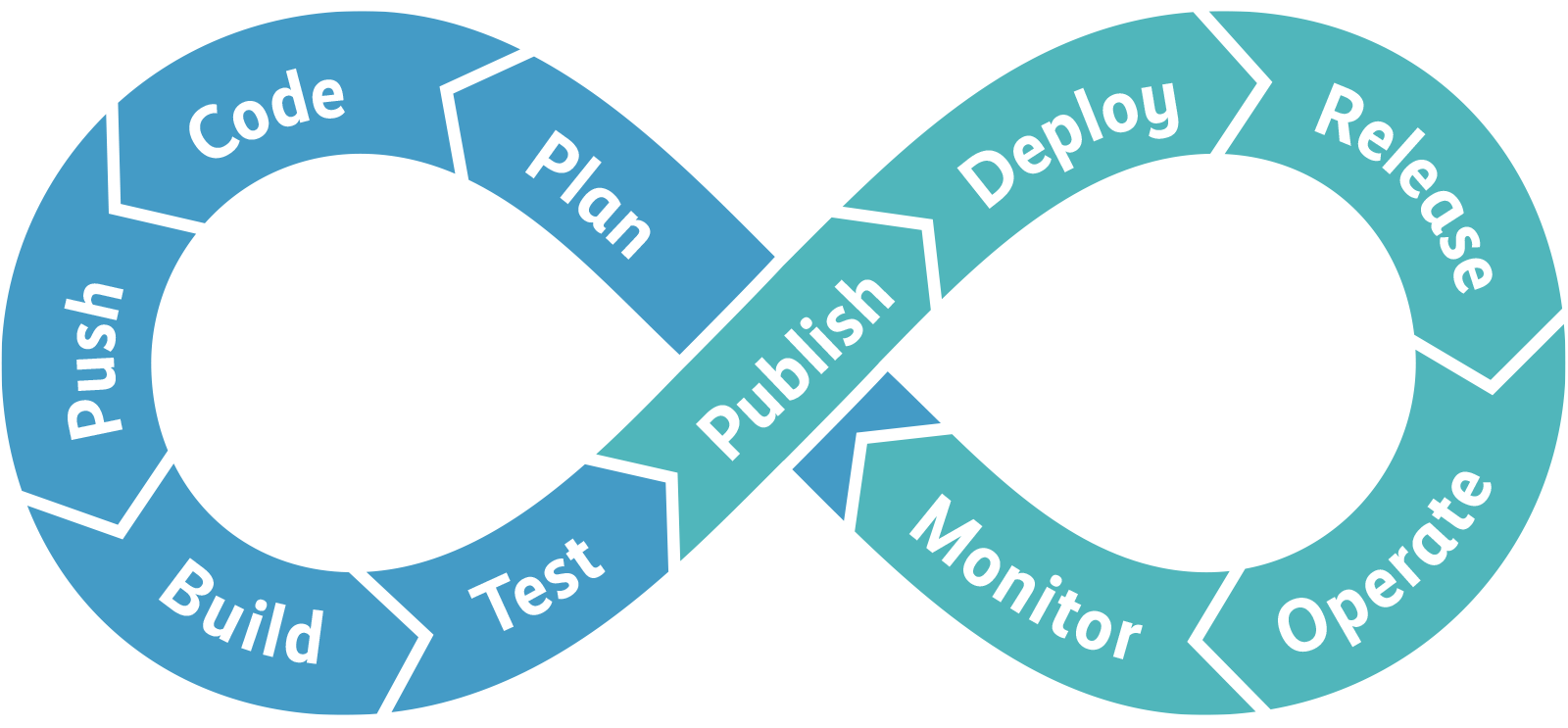
The specific development process contains two modifications in comparison to the orthodox DevOps development process:
- There's a split between DEPLOY and RELEASE that is inversely executed as in the orthodox DevOps process
- Staging can happen automatically and independently from the release of the feature leading to a clean pipeline implementation. Continuous from PUSH to DEPLOY over all the stages.
- There's a PUBLISH step where the technical component is formally checked before accepting it as candidate to deployment in production
- A certain criteria can be established to reject content in the cloud. The cloud runtime is really different from the on-prem mainly because a perimeter cannot be assumed anymore and thus, relying on reaction didn't seem fast enough.
These two modifications in the development process enable the organization to decouple the iterations in the development of a technical component from the release of new features to the end customers and establish a gate that checks the quality of the software produced.
This strategy permits mainstreaming two development techniques that were, until now, impossible to scale up in the organization:
- Trunk-based development
- Continuous deployment
Being able to roll out those two techniques, together with the efficiency win of diminishing the amount of staging - feasible due to the gate introduction - minimize the overhead - and thus the time - to bring change to production. The mean time to repair (MTTR) and the time to market (TTM) reache a very low minimum limit.
The technology stack architecture can scale up to all the technical components if the service in charge of bringing them into production has a standard interfece. Hence, the interface of the deployment service looks like this:
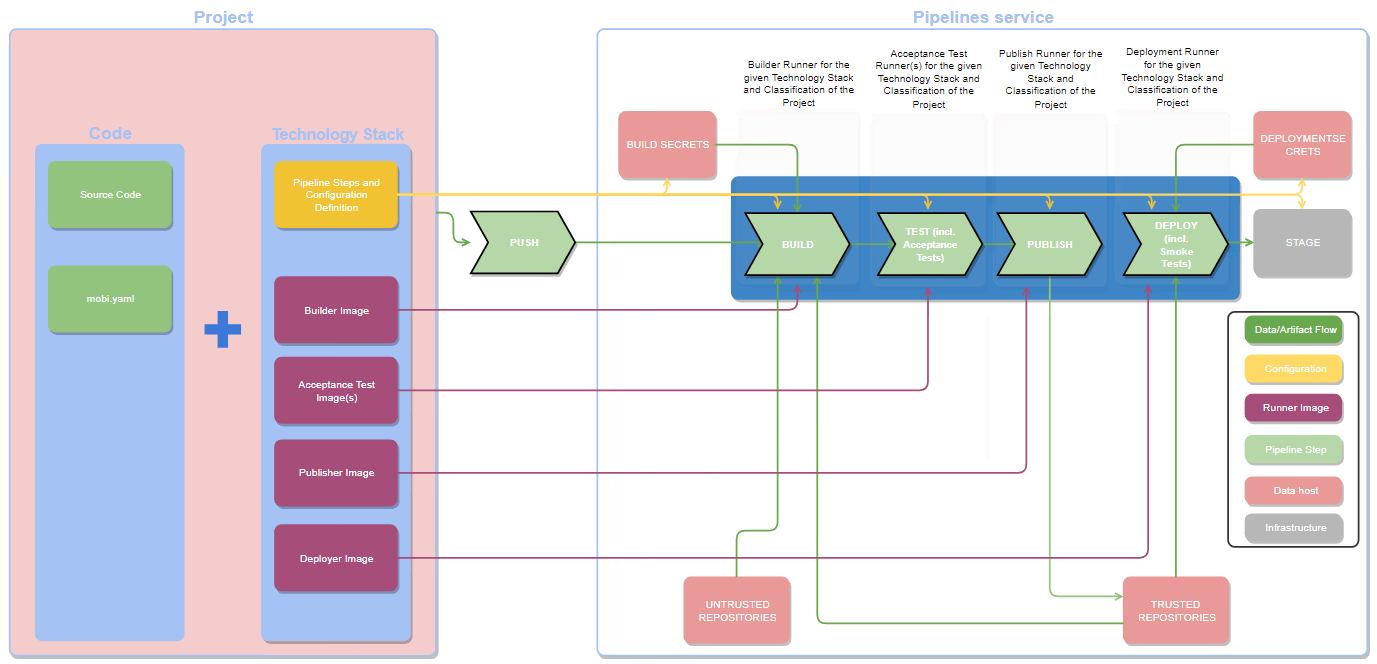
This architecture of the service that implements the automated part of the development process is the base that brings the platform up. Technology stacks are developed over the common delivery service and offered to the feature teams as technical component type. On the other side, the delivery service provides operations, checks and visibility to the stakeholders and feature teams during the automatized part of the development process.
An additional level is needed, though, governance. In order to leverage impact, the platform must serve only standardized productive technical components. This means that an entity must decide what technical components exist and what mission they have. This entity takes the form of a "Domain architect" - a domain architect is in charge of the technical components that serve the business applications present in his/her domain(s). This role is then responsible to initialize the technical components, share ownership of them with the feature teams and decommission them once they're not productive anymore.
The use model is then clear and elegant: Technical components are initialized by architects when its need is confirmed. The feature teams use technology stacks to develop them in a standardized and DevOps way. They retain ownership at all times and all ends of the development lifecycle of the technical components. In case a technical component wouldn't be needed, the domain architect can decommission it at anytime.
Collaboration between teams - in terms of modification of the technical components - should also be leveraged by the platform without degrading responsibility and ownership. The adoption of DevOps, trunk-based development and continuous deployment ensure that there's a direct link between the state of the repository and the state of the production runtime. All additions to the main branch of the technical component must respect this ownership model and thus, the pull requests are regulated accordingly: Feature teams members are - together with the domain architect - the only owners of the technical component's repositories because the responsibilit lies in them. Any change to the main branch of a repository must either be directly performed or approved by a member of the feature team that owns the technical component.
Iterating the platform #
The platform is a living object. The technology stacks must be updated and so must their technical components be. This means that lifecycle effort is not only passed through the platform but also created by the platform itself.
It's, however clear that the origin of the lifecycle lies in the technology stacks and can be streamed down to the consumer technical components. This lifecycle, since it's a version propagation, can be done following the development process and thus, fully automatic under the supervision of the owners of the technical components.